In this sequence of posts, I explain how to use the
Model Browser provided by
MoDisco to inspect an EMF model.
In the first three posts, I have described
how to directly access to instances of a given type,
how to navigate through the model elements and
how to customize the browser.
In this last post, I will now describe how to create and execute queries on model elements directly from the browser.
The features presented in the previous posts, allow you to navigate through the elements of your model by traversing the links. You can also highlight some characteristics of specific elements by defining a customization which dynamically change their rendering (icon, label, font, color, etc).
But in some situations, you would like to calculate values from model elements. These values could be of basic types (numbers or strings) or could be other model elements.
MoDisco provides a mechanism to execute queries interactively on model elements selected in the Model Browser. First, I will explain how to execute queries, and we will see later in this post how to declare and implement them.
There are two possibilities to execute a query.
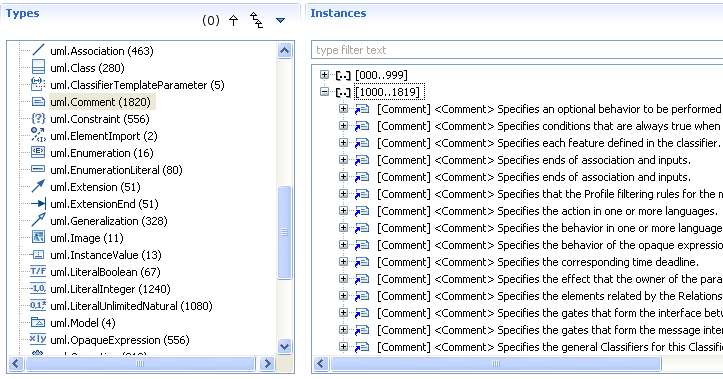
The first one consists in selecting model elements in the browser and clicking on the menu "
Execute Query ...". It opens the "
Query Execution" view which contains two main parts:
- The elements on which to execute the query. It is filled with the elements you have selected, but you can also remove elements from this list or drag&drop new elements from the browser.
- The registered queries which can be executed on the selected elements
When you click on "
Execute" the selected query is executed on each model element and the result is displayed in a table (more possibilities will be provided with future versions).
The table displays each returned value on a line. If the result is a basic type, the table contains only one column. But if the result is a model element, the table contains several columns:
- A colum "Label" which contains the calculated label of the object.
- A column "Metaclass" which contains the type of the object
- A column "/eContainer" which contains the parent of the object
- A column "Query Context" which contains the object for which the query has returned the object
- A column for each attribute of the corresponding metaclass
- A column for each reference of the corresponding metaclass (for nary references, the tablel displays the number of related objects).
On each line, it is possible to re-execute a query or to browse the selected element with the model browser.
To execute a query from the browser, the second possibility consists in adding the query to a model element in the browser by clicking on the menu "Dispaly Queries on Selected Element":
A dialog is opened with all the applicable queries:
The selected query is added to the model element. When you click on this query, it is executed and the result is displayed under the query:
Now, to create your own query, the first step consists in creating a QuerySet in a MoDisco project: right-click on the project, select the menu "New>Other" and select "MoDisco / QuerySet model":
Give a name to your new QuerySet and MoDisco creates it in the project:
A QuerySet is a model which contains the declaration of the queries. The new QuerySet is empty. So, to start declaring the queries, just double-click on the QuerySet to open it with the dedicated editor:
Now, you need to associate the QuerySet to a metamodel: all the queries will apply on model elements of the corresponding models.
Let's say we want to declare queries for UML model elements. This association is done in two steps:
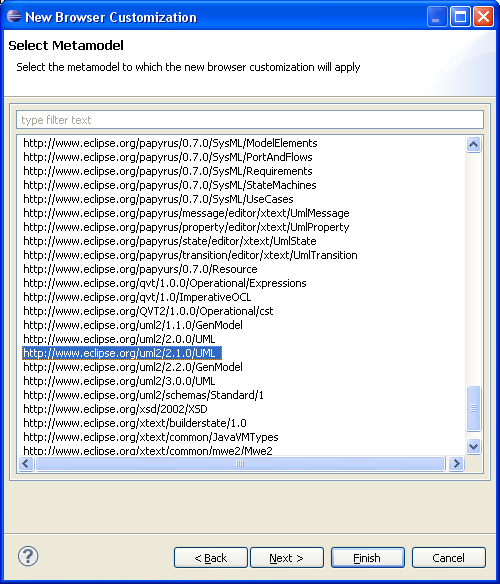
- Load the ECore definition of the metamodel: right click on the ModelQuerySet instance, select the menu "Load meta-model ressource" and select the right ECore definition.
- Associate this metamodel to the QuerySet: double-click on the ModelQuerySet instance to open its property view, click on the button in the "Associated Metamodels" property field, and select the metamodel.
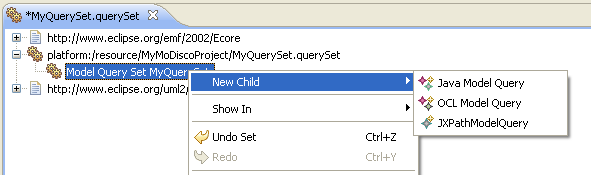
Now, you can start declaring the queries: right-click on the ModelQuerySet instance and click on the "New Child" menu. You can declare queries of three kinds: Java, OCL or XPath.
For each query, you have to declare its name, its scope (on which elements the query is applicable), its return type and its multiplicity (lower and upper bounds). Implementing the body of the query depends on the kind of query:
- OCL: enter an OCL expression in the "Query" property
- XPath: enter an XPath expression in the "Query" property
- Java: enter the name of a Java class which implements the query